Premise Data has a global network of Contributors who are paid to provide ground-level insights through Premise’s mobile app. As of January 2020, over 1.4 million on-the-ground local citizen Contributors are paid to answer surveys and map places across the globe. On average, Contributors are submitting hundreds of thousands of responses to “tasks” per day. Many of those submissions entail location-based discovery places like restaurants, health facilities, schools, etc. The data is used to better understand economic development and population’s access to health services. Such projects are of particular importance to Premise’s clients like The Bill & Melinda Gates Foundation, USAID and many others.
In order to process the sometimes hundreds of submissions that represent the one authoritative location for a particular facility, Premise’s data scientists have developed an algorithm called ‘Place Harmonizer’ (pH) to conflate the hundreds of submissions that represent one facility to one high confidence location to determine the authoritative location for that facility.
Methods
Premise’s Contributors submit three pieces of data that enable Premise’s data scientists to algorithmically conflate many data points for the same location down to one authoritative location:
- Cartesian coordinate (latitude and longitude)
- The name of the place
- A photo of the place
Cartesian Coordinate
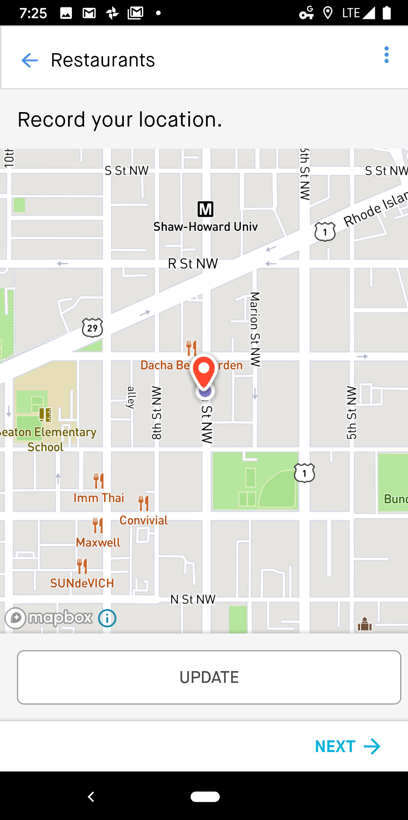
Example of how one would record a location within the Premise app
First, spatial clustering of latitude and longitude is used to group submissions together. This is aligned with Waldo Tobler’s First Law of Geography, which states that “everything is related to everything else, but near things are more related than distant things.”
A variable to limit the maximum search distance for submission points (latitude, longitude) is defined for each type of facility. For example, the radius of submitted locations to be grouped for pharmacies is smaller than the maximum search radius for hospitals. Generally speaking, hospitals occupy a larger area of land, and are spaced further apart across a landscape. Pharmacies tend to occupy a smaller footprint and are spaced closer together across a landscape.
Name
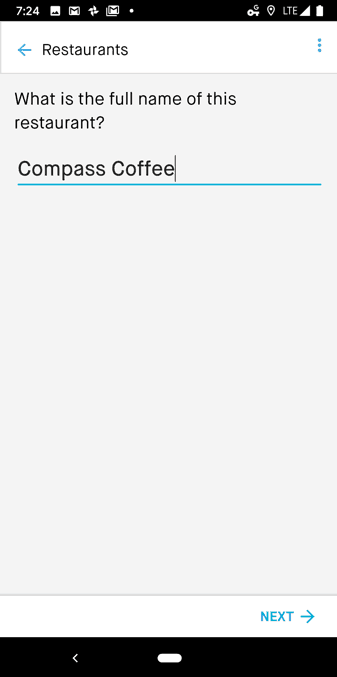
Sample name submission for a place within the Premise app
Second, once a spatial cluster is defined, Premise’s place harmonization algorithm will analyze the names of the facility as submitted by the Premise Contributors for each cluster. This step allows the algorithm to determine if the submissions have a similar name and stay clustered or have a different name and should be split apart into a unique cluster (facility name).
Given that Premise Contributors manually enter the name of the facility via a smartphone keyboard, the algorithm must sort out a wide range of names that might describe a facility. As a result, Premise’s data scientists have modified the Term Frequency-Inverse Document Frequency (TF-IDF) algorithm to accommodate this phenomenon.
The advantage of this modification allows the algorithm to be language-agnostic; in other words, it not only works when submissions are in English but also functions seamlessly in the 28 other languages in which our Contributors submit data (e.g. Arabic, Swahili, Tagalog, etc.).
Photograph
 Sample photo submission within the Premise app
Sample photo submission within the Premise app
Third, Contributors submit a photo of the outside of the facility. These photos are extremely valuable to represent the up-to-date condition of a place. The photos are also used for visual validation that the place is true to what our Contributors are actually submitting.
Premise’s data scientists have also used machine learning object character recognition tools on the photos to automatically extract all text observed within the photo. That text has then been used to help validate the name of the place that our Contributors submit. Most importantly, the photos serve as a means to do a final verification that multiple submissions should be joined into one authoritative place.
Conclusion
Crowdsourced data continues to prove essential to discovery and ground-truthing important places around the world. Premise considers the conflated places using our internally developed Place Harmonizer algorithm as foundational to knowing where facilities are located and to getting places mapped comprehensively across a landscape.
If you want to learn more about how you can deploy Premise for your organization please contact [email protected] or visit our website, premise.com.