A key aspect of Premise as a crowd empowered platform is the geospatial data that we collect from around the world.
This data has locational components such as latitude and longitude which provide opportunities for insightful, value-added analysis. At Premise the privacy and safety of our users is paramount and so we rigorously anonymize our data, allowing us to perform subnational analysis while protecting our users’ privacy.
The Problem with Geospatial Data
A major challenge when it comes to working with geospatial data is that it can be very computationally expensive. Failure to optimize these calculations can cost time and money. With over 2.75 million unique contributors making over 100M+ submissions to date, processing and analyzing this data quickly is essential.
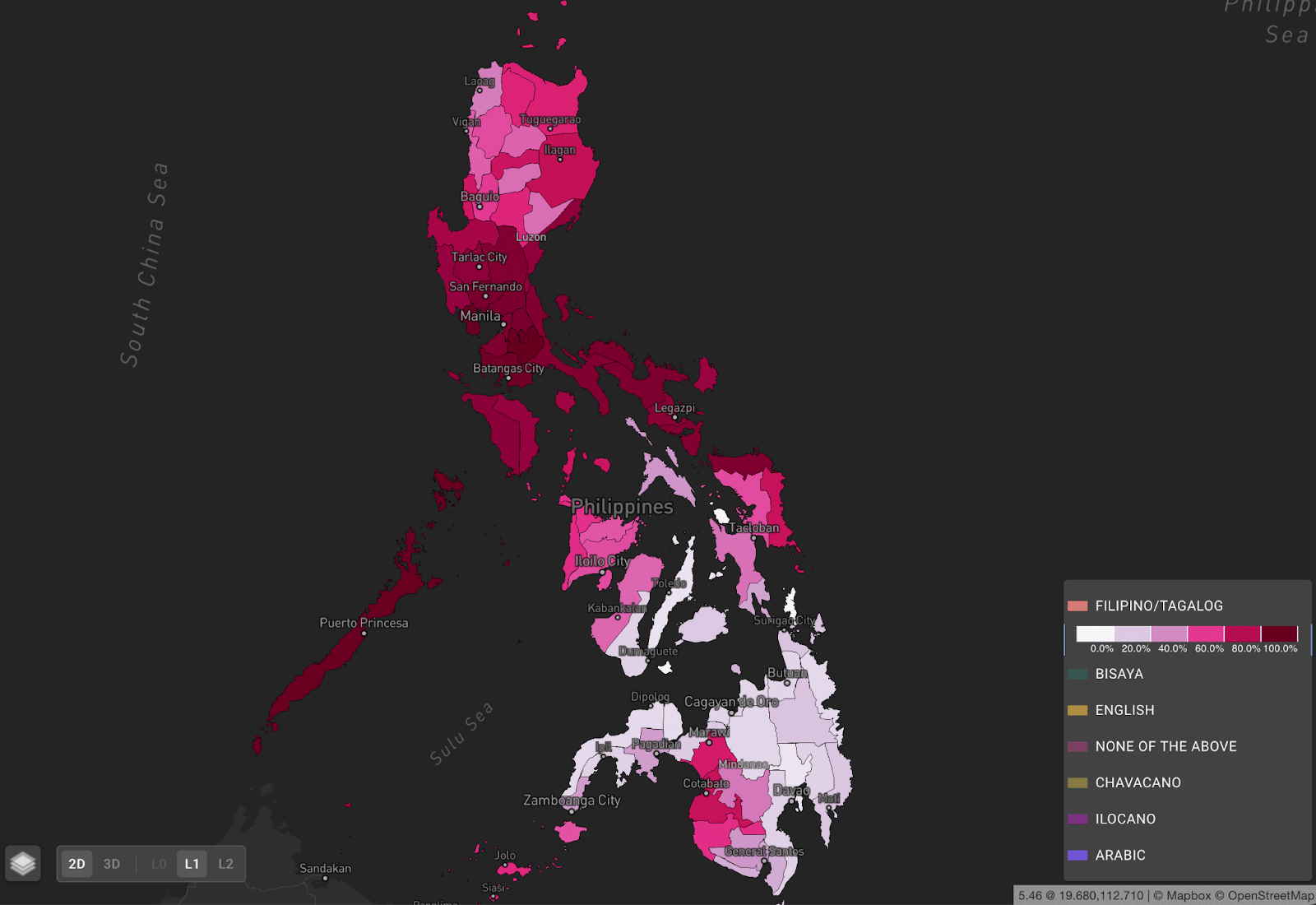
Premise demographic data displaying the Philippines by province the percentage of population that primarily speak Filipino/Tagalog
One way the Premise data science team has focused on turning this wealth of data into products for our customers is by creating a demographics dataset that aggregates our demographic data to administrative boundaries at different levels, i.e., national or state/province. This gives us breakdowns of demographic information such as ethnicity, language, religion, and more as seen in the example above.
What We Did
We turned to Google BigQuery in order to perform high speed geospatial calculations on a global scale. This allowed us to address diverse data needs to include synthesizing up to hundreds of millions of records and eliminating potential processing bottlenecks.
With data scattered across different projects and multiple tables, we needed to incorporate global population, geospatial tables, anonymized user locations and history, and the results of our demographic data into one table.
We had previously analyzed this data using Google Colab python notebooks which necessitated running the notebook 1000+ times due to memory limitations of the service.
We wanted to achieve global coverage in a single step, necessitating a different environment. An additional challenge this analysis posed is that it would require millions of spatial joins, or where you join pieces of data that are in the same place or region. This tends to be very computationally expensive.
Why BigQuery was the Ideal Solution
With Contributors moving as they go about their lives, we needed to process user behavior and make sure we would assign them to the correct state or district to ensure accuracy in our demographic breakdowns. BigQuery provided a solution to all of our challenges for this analysis.
Features of BigQuery made it an obvious choice for this challenge. It helped us seamlessly utilize Google Cloud’s scalable memory while allowing us to process our data quickly at a global scale. In the process, we were able to dramatically speed up the millions of spatial joins we had to do.
The depth of features and flexibility in BigQuery would allow us to perform all calculations from sample size calculations to margins of error and confidence intervals inside the platform. For instance, we had to combine user locations with global time zones and process many points of location information for users to assign them to the correct regions.
What We Learned
The end result was that we offloaded all major computation to BQ with a SQL query combining population data, contributor submission data, our geospatial tables, and user information.
We selected demographic data only from recently active users, conducted a spatial join to determine the administrative area a user belonged to so we could aggregate data, aggregated the data with group bys, and then utilized our population data to calculate margins of error and confidence intervals for our data.
Processing demographic data involved touching tables including over 146 million rows totaling over 731 GB of data. By using BigQuery and optimizing our SQL we only processed 3.9GB and it took a mere 12 seconds to complete what took weeks during the pilot. Our user location queries processed over 8TB of data in under 10 minutes.
These rapid calculations will allow us to keep our global demographic product updated in near real time, providing a better customer experience and freeing the data science team to focus on improving the product instead of simply trying to complete the analysis.
The project is a prime example of how Premise Data is leveraging tools in the Google Cloud to efficiently create global products for our clients. Our next projects involve utilizing the H3 spatial index libraries built into BigQuery as a different approach to aggregating safety data.
The behind the scenes work Google does allows us as Data Scientists to focus on creating value added products and synthesizing varied data sources, freeing us to utilize computationally expensive geospatial functions and process terabytes of data in minutes thanks to Google’s infrastructure.
Get in touch with us today to learn more about how we can save you time and money by developing long term solutions to your most pressing business problems.